






















Both data warehouses and data lakes can hold large amounts of data for analysis. As you may recall, data warehouses contain curated, structured data, have a predesigned schema that is applied when the data is written, call on large amounts of CPU, SSDs, and RAM for speed, and are intended for use by business analysts. Data lakes hold even more data that can be unstructured or structured, initially stored raw and in its native format, typically use cheap spinning disks, apply schemas when the data is read, filter and transform the raw data for analysis, and are intended for use by data engineers and data scientists initially, with business analysts able to use the data once it has been curated..
Data lakehouses, such as the subject of this review, Dremio, bridge the gap between data warehouses and data lakes. They start with a data lake and add fast SQL, a more efficient columnar storage format, a data catalog, and analytics.


Dremio describes its product as a data lakehouse platform for teams that know and love SQL. Its selling points are
- SQL for everyone, from business user to data engineer;
- Fully managed, with minimal software and data maintenance;
- Support for any data, with the ability to ingest data into the lakehouse or query in place; and
- No lock-in, with the flexibility to use any engine today and tomorrow.
According to Dremio, cloud data warehouses such as Snowflake, Azure Synapse, and Amazon Redshift generate lock-in because the data is inside the warehouse. I don’t completely agree with this, but I do agree that it’s really hard to move large amounts of data from one cloud system to another.
Also according to Dremio, cloud data lakes such as Dremio and Spark offer more flexibility since the data is stored where multiple engines can use it. That’s true. Dremio claims three advantages that derive from this:
- Flexibility to use multiple best-of-breed engines on the same data and use cases;
- Easy to adopt additional engines today; and
- Easy to adopt new engines in the future, simply point them at the data.
Competitors to Dremio include the Databricks Lakehouse Platform, Ahana Presto, Trino (formerly Presto SQL), Amazon Athena, and open-source Apache Spark. Less direct competitors are data warehouses that support external tables, such as Snowflake and Azure Synapse.
Dremio has painted all enterprise data warehouses as their competitors, but I dismiss that as marketing, if not actual hype. After all, data lakes and data warehouses fulfill different use cases and serve different users, even though data lakehouses at least partially span the two categories.
Dremio Cloud overview
Dremio server software is a Java data lakehouse application for Linux that can be deployed on Kubernetes clusters, AWS, and Azure. Dremio Cloud is basically the Dremio server software running as a fully managed service on AWS.
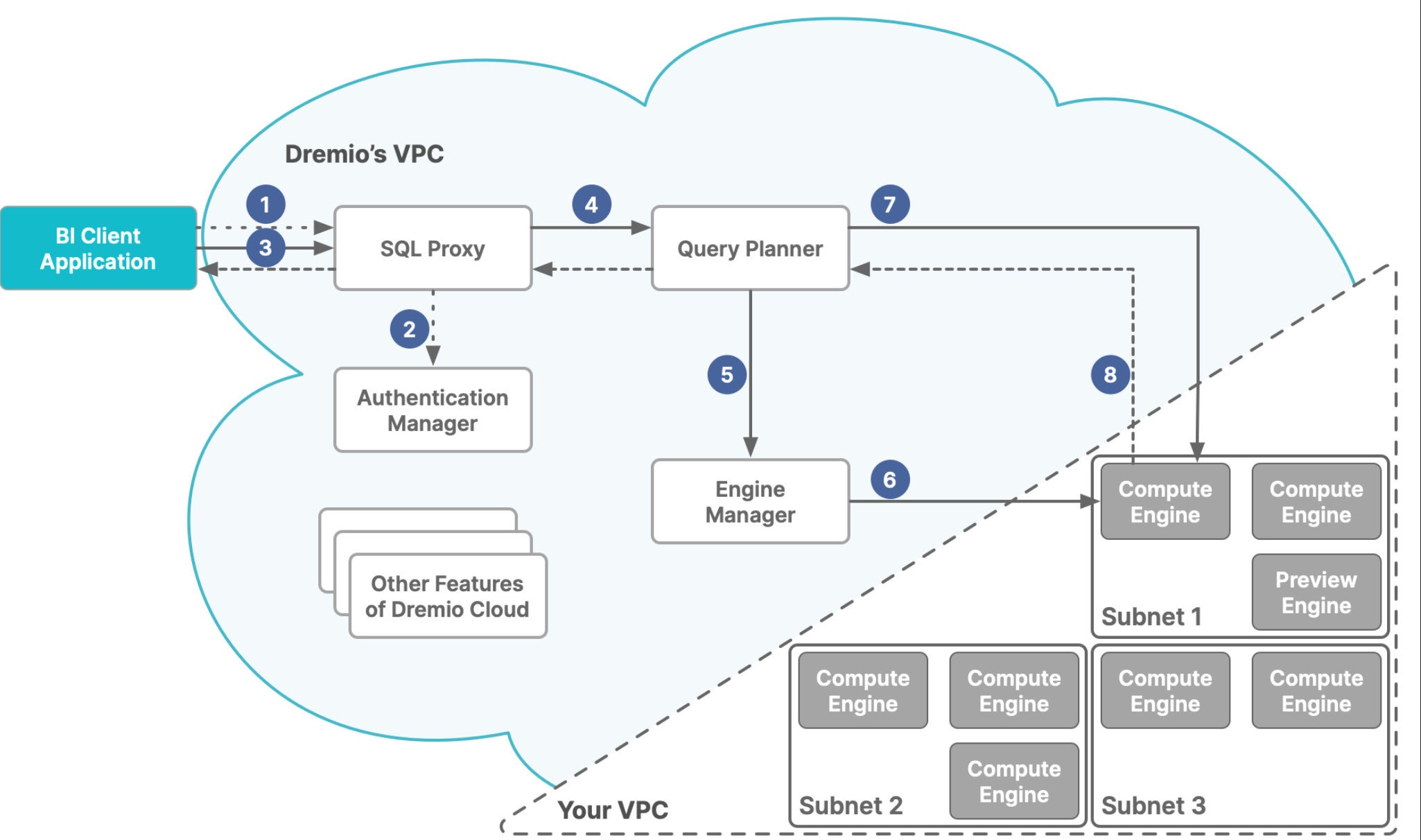
Dremio Cloud’s functions are divided between virtual private clouds (VPCs), Dremio’s and yours, as shown in the diagram below. Dremio’s VPC acts as the control plane. Your VPC acts as an execution plane. If you use multiple cloud accounts with Dremio Cloud, each VPC acts as an execution plane.
The execution plane holds multiple clusters, called compute engines. The control plane processes SQL queries with the Sonar query engine and sends them through an engine manager, which dispatches them to an appropriate compute engine based on your rules.
Dremio claims sub-second response times with “reflections,” which are optimized materializations of source data or queries, similar to materialized views. Dremio claims raw speed that’s 3x faster than Trino (an implementation of the Presto SQL engine) thanks to Apache Arrow, a standardized column-oriented memory format. Dremio also claims, without specifying a point of comparison, that data engineers can ingest, transform, and provision data in a fraction of the time thanks to SQL DML, dbt, and Dremio’s semantic layer.
Dremio has no business intelligence, machine learning, or deep learning capabilities of its own, but it has drivers and connectors that support BI, ML, and DL software, such as Tableau, Power BI, and Jupyter Notebooks. It can also connect to data sources in tables in lakehouse storage and in external relational databases.
 IDG
IDG
Dremio Cloud is split into two Amazon virtual private clouds (VPCs). Dremio’s VPC hosts the control plane, including the SQL processing. Your VPC hosts the execution plane, which contains the compute engines.
Dremio Arctic overview
Dremio Arctic is an intelligent metastore for Apache Iceberg, an open table format for huge analytic datasets, powered by Nessie, a native Apache Iceberg catalog. Arctic provides a modern, cloud-native alternative to Hive Metastore, and is provided by Dremio as a forever-free service. Arctic offers the following capabilities:
- Git-like data management: Brings Git-like version control to data lakes, enabling data engineers to manage the data lake with the same best practices Git enables for software development, including commits, tags, and branches.
- Data optimization (coming soon): Automatically maintains and optimizes data to enable faster processing and reduce the manual effort involved in managing a lake. This includes ensuring that the data is columnarized, compressed, compacted (for larger files), and partitioned appropriately when data and schemas are updated.
- Works with all engines: Supports all Apache Iceberg-compatible technologies, including query engines (Dremio Sonar, Presto, Trino, Hive), processing engines (Spark), and streaming engines (Flink).
Dremio data file formats
Much of the performance and functionality of Dremio depends on the disk and memory data file formats used.
Apache Arrow
Apache Arrow, which was created by Dremio and contributed to open source, defines a language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware like CPUs and GPUs. The Arrow memory format also supports zero-copy reads for lightning-fast data access without serialization overhead.
Gandiva is an LLVM-based vectorized execution error for Apache Arrow. Arrow Flight implements RPC (remote procedure calls) on Apache Arrow, and is built on gRPC. gRPC is a modern, open-source, high-performance RPC framework from Google that can run in any environment; gRPC is typically 7x to 10x faster than REST message transmission.
Apache Iceberg
Apache Iceberg is a high-performance format for huge analytic tables. Iceberg brings the reliability and simplicity of SQL tables to big data, while making it possible for engines such as Sonar, Spark, Trino, Flink, Presto, Hive, and Impala to safely work with the same tables, at the same time. Iceberg supports flexible SQL commands to merge new data, update existing rows, and perform targeted deletes.
Apache Parquet
Apache Parquet is an open-source, column-oriented data file format designed for efficient data storage and retrieval. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk.
Apache Iceberg vs. Delta Lake
According to Dremio, the Apache Iceberg data file format was created by Netflix, Apple, and other tech powerhouses, supports INSERT/UPDATE/DELETE with any engine, and has strong momentum in the open-source community. By contrast, again according to Dremio, the Delta Lake data file format was created by Databricks, supports INSERT/UPDATE with Spark and SELECT with any SQL query engine, and is primarily used in conjunction with Databricks.
The Delta Lake documentation on GitHub begs to differ. For example, there is a connector that allows Trino to read and write Delta Lake files, and a library that allows Scala and Java-based projects (including Apache Flink, Apache Hive, Apache Beam, and PrestoDB) to read from and write to Delta Lake.
Dremio query acceleration
In addition to the query performance that is derived from the file formats used, Dremio can accelerate queries using a columnar cloud cache and data reflections.
Columnar Cloud Cache (C3)
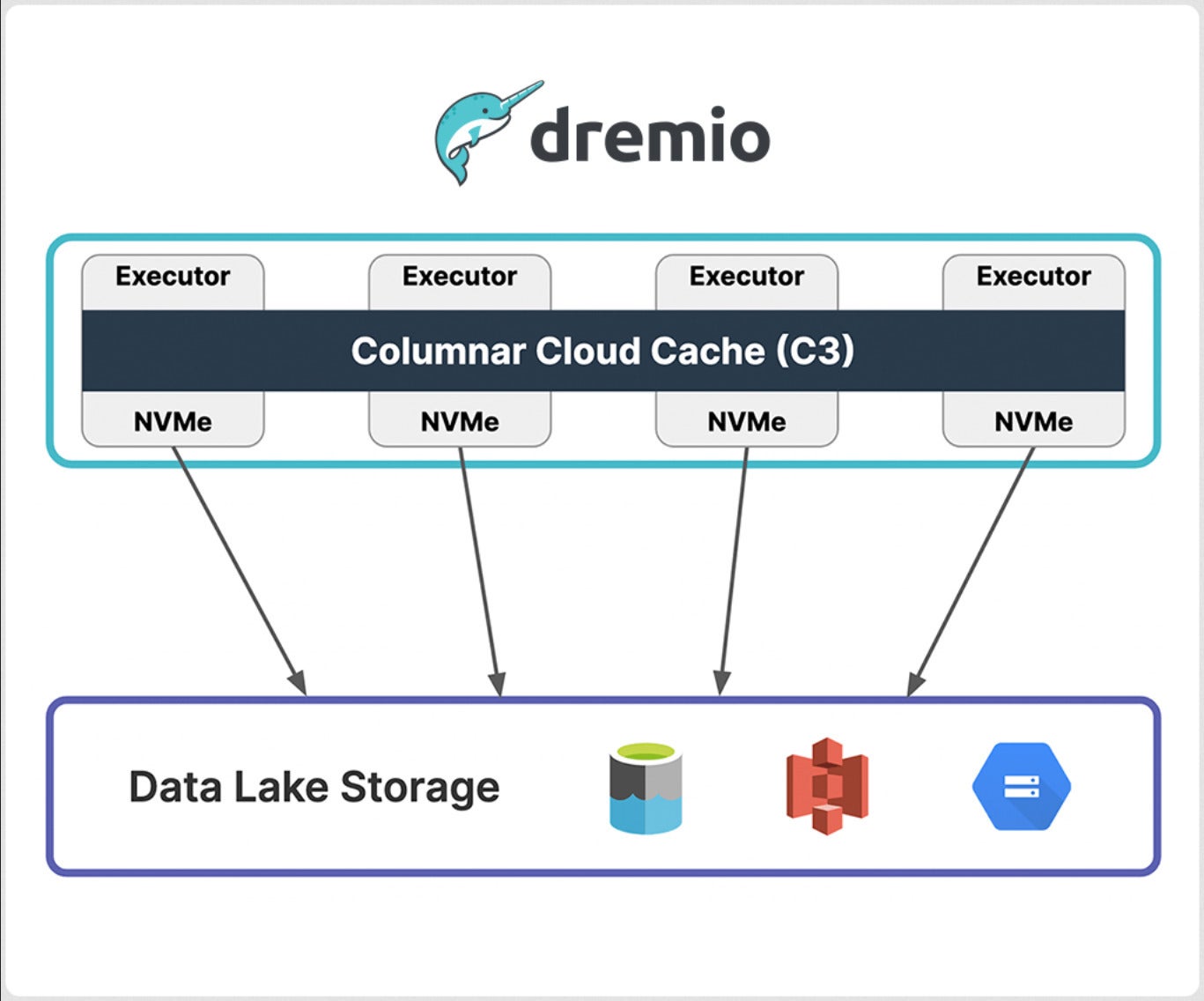
Columnar Cloud Cache (C3) enables Dremio to achieve NVMe-level I/O performance on Amazon S3, Azure Data Lake Storage, and Google Cloud Storage by using the NVMe/SSD built into cloud compute instances, such as Amazon EC2 and Azure Virtual Machines. C3 only caches data required to satisfy your workloads and can even cache individual microblocks within datasets. If your table has 1,000 columns and you only query a subset of those columns and filter for data within a certain timeframe, then C3 will cache only that portion of your table. By selectively caching data, C3 also dramatically reduces cloud storage I/O costs, which can make up 10% to 15% of the costs for each query you run, according to Dremio.
 IDG
IDG
Dremio’s Columnar Cloud Cache (C3) feature accelerates future queries by using the NVMe SSDs in cloud instances to cache data used by previous queries.
Data Reflections
Data Reflections enable sub-second BI queries and eliminate the need to create cubes and rollups prior to analysis. Data Reflections are data structures that intelligently precompute aggregations and other operations on data, so you don’t have to do complex aggregations and drill-downs on the fly. Reflections are completely transparent to end users. Instead of connecting to a specific materialization, users query the desired tables and views and the Dremio optimizer picks the best reflections to satisfy and accelerate the query.
Dremio Engines
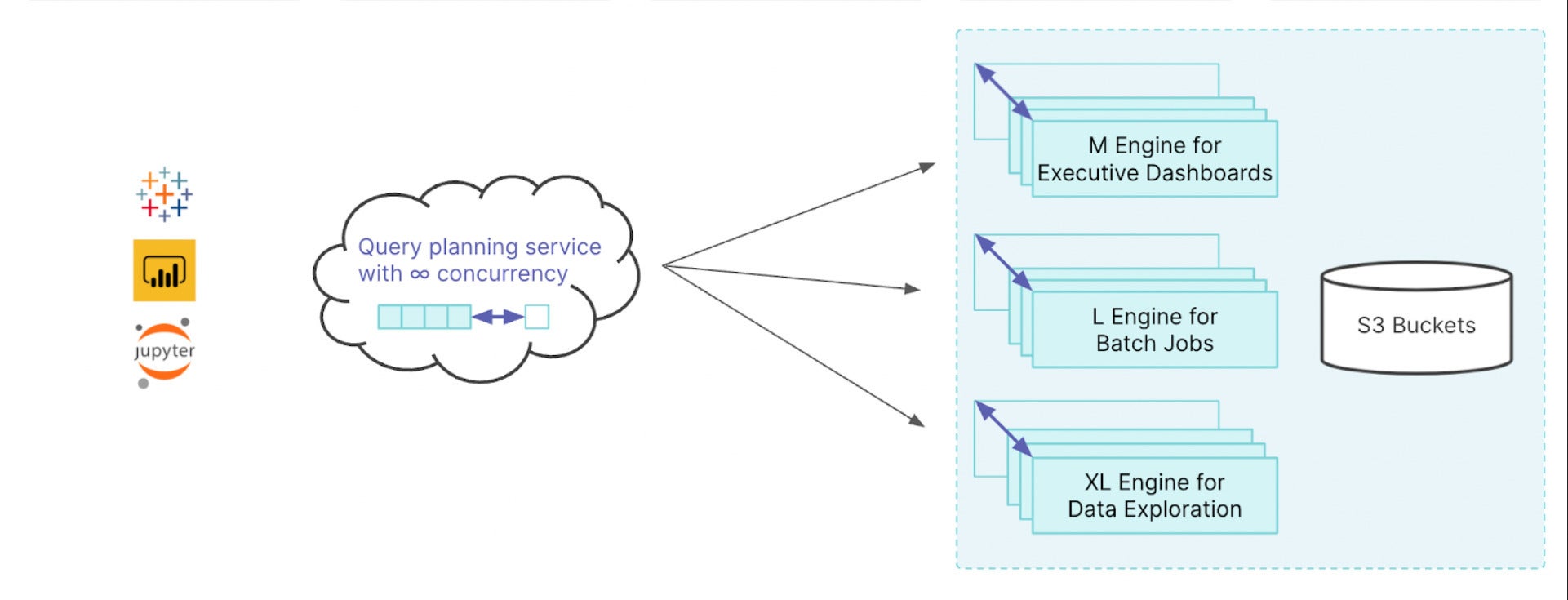
Dremio features a multi-engine architecture, so you can create multiple right-sized, physically isolated engines for various workloads in your organization. You can easily set up workload management rules to route queries to the engines you define, so you’ll never have to worry again about complex data science workloads preventing an executive’s dashboard from loading. Aside from eliminating resource contention, engines can quickly resize to tackle workloads of any concurrency and throughput, and auto-stop when you’re not running queries.
 IDG
IDG
Dremio Engines are essentially scalable clusters of instances configured as executors. Rules help to dispatch queries to the desired engines.
Getting started with Dremio Cloud
The Dremio Cloud Getting Started guide covers
- Adding a data lake to a project;
- Creating a physical dataset from source data;
- Creating a virtual dataset;
- Querying a virtual dataset; and
- Accelerating a query with a reflection.
I won’t show you every step of the tutorial, since you can read it yourself and run through it in your own free account.
Two essential points are that:
- A physical dataset (PDS) is a table representation of the data in your source. A PDS cannot be modified by Dremio Cloud. The way to create a physical dataset is to format a file or folder as a PDS.
- A virtual dataset (VDS) is a view derived from physical datasets or other virtual datasets. Virtual datasets are not copies of the data so they use very little memory and always reflect the current state of the parent datasets they are derived from.
Source by www.infoworld.com





{kind=link}